学院新闻
预测精准度+10%,库存-70%,MIT团队如何做到?
在家装行业,库存管理一直是企业运营中的一大难题,尤其是面对不规则需求产品(Lumpy Products)时,传统的需求预测模型往往难以应对。针对这一难题,在2025年MIT SCALE Connect的供应链挑战(Supply Chain Challenge)中,由MIT Global SCALE Network 各中心的6位学生组成的团队(我院陈余恒作为宁创同学代表)成功提出了一套优化方案,并在竞赛中获奖。

团队以某一生产管道产品的企业为例,该企业需求呈现出典型的“不规则需求”特征,这意味着其销售模式并非持续稳定,而是表现出长时间无销售和突发性需求高峰两种极端情况。
而这一特点给库存管理带来了双重挑战:一方面,某些产品可能数周甚至数月没有销售记录,导致库存积压,占用大量资金,同时增加了库存管理的难度;另一方面,需求可能在短时间内突然激增,导致传统预测模型难以准确捕捉这一变化,这容易导致库存不足,影响客户满意度并增加运营成本。
为了应对这一挑战,团队首先对数据进行了深入分析。通过对月度、周度以及物料级别的需求数据进行汇总,发现传统的需求模式并不明显。因此,团队采用了ABC分类法,基于需求量对物料进行分类,如某一物料占据了总需求的36%,这说明该物料属于企业核心产品之一。
此外,团队应用了SPC方法(Syntetos-Boylan Approximation),结合平方变异系数和平均需求间隔等指标,将不规则需求产品细分为六个类别,这一分类方法为后续的预测模型构建奠定了基础。
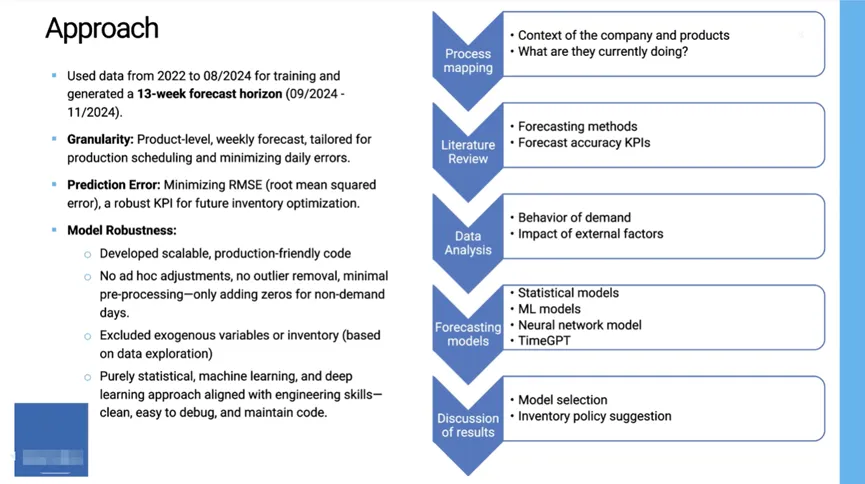
在构建预测模型时,团队还评估了可能影响需求的内外部变量,包括库存水平、水泥发货量、建筑业GDP、经济监测指标等。然而,数据分析显示,这些变量与需求之间的相关性较弱,因此团队决定在模型中排除这些外部变量,专注于产品本身的需求模式。模型构建的关键步骤包括:深入了解企业的业务模式和产品需求特点、研究各种预测方法、确定关键的性能指标(KPI)、探索多种预测模型(包括统计模型、机器学习和神经网络模型)、确保模型能够捕捉不同方面的需求波动,并通过交叉验证和超参数调优、确保模型的准确性和稳定性。
随后,团队使用了2022年至2024年8月的数据进行模型训练,并生成了2024年9月至11月的13周预测。预测的粒度精确到每周,以满足生产调度的需求,并最小化日常误差。在评估模型性能时,团队选择了均方根误差(RMSE)作为核心指标,相比于传统的平均绝对百分比误差(MAPE),RMSE在处理零需求时更为可靠,且能够更好地捕捉需求波动中的误差幅度,特别适合不规则需求预测。
团队共运行了13种不同的预测模型,并通过交叉验证和超参数调优,确保每个SKU的RMSE最小化。最终,XGBoost和N-HiTS模型表现最为出色,分别适用于23个和18个SKU。然而,真正的突破来自于集成模型(Ensemble Model),该模型在84个SKU中的82个上表现最优,平均预测准确率提升了10.2%,部分SKU的RMSE甚至降低了55.5%。

通过集成模型的精准预测,团队还开发了一个自动化Python脚本,能够快速处理76个预测模型,并为每个SKU生成最优的加权集成预测。这一改进直接转化为更高效的库存管理,降低了成本并提升了客户服务水平。
具体来说,团队提出的库存优化策略包括:根据预测误差调整安全库存水平,以更好地应对需求不确定性;在低波动性产品类别中,36个产品的库存有望大幅减少,而在低需求类别中,12个产品和5个间歇性需求产品则需要增加库存,以减少缺货风险。通过集成模型的应用,该企业有望将平均库存从56,000单位减少到17,000单位,同时保持现有的服务水平。

团队的库存优化方案带来了以下关键洞察:统计模型(如季节性模型、朴素模型)在间歇性需求预测中表现良好,而XGBoost和N-HiTS在处理复杂需求模式时表现出色;集成模型显著降低了预测误差,但需要注意过度拟合的风险;根据需求波动性调整服务水平,确保安全库存与预测误差相匹配,能够更好地管理不确定性。
基于这些洞察,团队还提出了以下建议:建立结构化模型评估框架,确保模型的高效性和准确性;采用集成模型,以提升预测性能,特别是在不规则需求场景下;根据需求波动性动态调整库存策略,确保在减少库存的同时,维持高服务水平。

通过先进的预测模型和库存优化策略,团队成功解决了不规则需求带来的挑战,显著提升了库存管理效率,降低了运营成本,并确保了客户满意度。这一案例不仅为家装行业提供了宝贵的经验,也为其他面临类似挑战的企业提供了可借鉴的解决方案。未来,我院将继续探索更多创新技术,进一步优化供应链管理,为企业提供更具前瞻性的解决方案。
返回上一级